Ethical Alignment, Fairness, and Value Assessment
Research on improving the ethical alignment of LLMs, reducing bias, and ensuring fairness across different user groups and applications

Ethical Alignment, Fairness, and Value Assessment
Research on Large Language Models in Ethical Alignment, Fairness, and Value Assessment

GuardAgent: A New Frontier in LLM Safety
Protecting AI agents through dynamic safety monitoring

The Personalization Paradox in LLMs
Balancing Safety and Utility When Adapting to User Identity

Uncovering Hidden Biases in LLMs
A Psychometric Approach to Revealing Implicit Bias in AI Systems

Testing the Moral Boundaries of LLMs
A dynamic approach to evaluating AI value alignment

Pluralistic AI Alignment
Aligning AI with diverse human values through Pareto optimization

Building Responsible AI: A Developer's Toolkit
250+ resources to guide ethical foundation model development

Ethical Frontiers in LLM Development
Understanding unique ethical challenges of language models

Measuring Fairness in LLMs
A Unified Framework for Evaluating Bias in AI Models

A Practical Toolkit for LLM Fairness
Moving from theory to actionable bias assessment in AI

Exposing Biases in AI Image Generation
A comprehensive benchmark for evaluating social biases in text-to-image models

Addressing Gender Bias in AI Models
A comprehensive framework for assessment and mitigation

Balancing Safety & Helpfulness in LLMs
A resource-efficient approach to optimize competing objectives

Empowering Users to Reshape AI Companions
Understanding user strategies for correcting biased AI outputs

Building Safer AI Agents
Comprehensive Safety Architecture Development & Analysis

Detecting Bias in LLMs: A New Benchmark
Introducing SAGED: A Comprehensive Framework for Bias Detection and Fairness Calibration

Measuring Values in AI and Humans
A New Framework for Understanding AI Alignment

The Role-Play Paradox in LLMs
How role-playing enhances reasoning but creates ethical risks

When Strong Preferences Disrupt AI Alignment
How preference intensity affects AI safety and robustness

Cognitive Biases in Large Language Models
Comparative analysis of bias patterns across GPT-4o, Gemma 2, and Llama 3.1

Solving the Weak-to-Strong Alignment Challenge
A novel multi-agent approach for aligning powerful AI systems

Beyond Binary Bias Detection
A Nuanced Framework for Identifying Social Bias in Text

Flexible Safety for AI Systems
Adapting LLMs to diverse safety requirements at inference time

Decoding Digital Personalities
How LLMs Encode and Express Personality Traits

The Hidden Pattern of AI Bias
Revealing surprising similarities in bias across different LLM families

Uncovering LLM Bias Across Social Dimensions
Systematic evaluation reveals significant fairness issues in open-source models

Beyond Human Oversight: Safety in AI Models
Novel approaches for aligning superhuman AI systems

Training LLMs to Resist Manipulation
Teaching models when to accept or reject persuasion attempts

Ideology in AI: Uncovering LLM Biases
How language models reflect their creators' political perspectives

Fairness at the Frontlines: Rethinking Chatbot Bias
A novel counterfactual approach to evaluating bias in conversational AI

Safer AI Through Better Constraints
A novel approach to prevent LLMs from circumventing safety measures

The Myth of Self-Correcting AI
Why moral self-correction isn't innate in LLMs

Moral Self-Correction in Smaller LLMs
Even smaller language models can effectively self-correct unethical outputs

Detecting Bias in AI-Generated Code
A framework to identify and mitigate social bias in LLM code generation

AI Alignment in Finance: The LLM Ethics Test
Evaluating how language models handle financial ethics

The Open vs. Closed LLM Divide
How open-source models are reshaping AI accessibility and innovation

Explainable Ethical AI Decision-Making
A Contrastive Approach for Transparent Moral Judgment in LLMs

Multilingual Bias Mitigation in LLMs
How debiasing techniques transfer across languages

Balancing Bias Mitigation & Performance in LLMs
A Multi-Agent Framework for Ethical AI Without Compromising Capability

Uncovering Hidden Biases in LLMs
A novel self-reflection framework for evaluating explicit and implicit social bias

Uncovering Bias in AI Coding Assistants
New benchmark for detecting social bias in code generation models

Balancing Ethics and Utility in LLMs
A Framework for Optimizing LLM Safety without Compromising Performance

Detecting Bias in AI Conversations
New framework reveals hidden biases in multi-agent AI systems

Context-Aware Safety for LLMs
Moving beyond simplistic safety benchmarks to preserve user experience

Adaptive Safety Rules for Safer AI
Enhancing LLM Security Through Dynamic Feedback Mechanisms

The Security Gap in LLM Safety Measures
Why Reinforcement Learning falls short in DeepSeek-R1 models

Benchmarking LLM Steering Methods
Simple baselines outperform complex approaches

Ethical Guardrails for AI: A Checks-and-Balances Approach
Pioneering a three-branch system for context-aware ethical AI governance

Rethinking LLM Safety Alignment
A Unified Framework for Understanding Alignment Techniques

The Safety Paradox in Fine-Tuned LLMs
How specialized training undermines safety guardrails

Beyond Western Bias in AI
A New Framework for Multi-Cultural Bias Detection in LLMs

Detecting Bias in LLMs: A Framework for Safer AI
An adaptable approach for identifying harmful biases across contexts

Building Value Systems in AI
A psychological approach to understanding and aligning LLM values

Demystifying LLM Alignment
Is alignment knowledge more superficial than we thought?

Balancing AI Assistant Safety Through Model Merging
A novel approach to optimize Helpfulness, Honesty, and Harmlessness in LLMs

Measuring Bias in AI Writing Assistance
A groundbreaking benchmark to detect political and issue bias in LLMs

Smart Self-Alignment for Safer AI
Refining LLM safety with minimal human oversight

The Safety Paradox in Smarter LLMs
How enhanced reasoning capabilities affect AI safety

Building Trustworthy AI
Addressing Critical Challenges in Safety, Bias, and Privacy

Tackling Bias in Edge AI Language Models
Detecting and Mitigating Biases in Resource-Constrained LLMs

Balancing Safety and Utility in LLMs
A novel approach to resolve the safety-helpfulness trade-off in AI systems

Debiasing LLMs with Gender-Aware Prompting
A novel approach that reduces bias without sacrificing performance

The Paperclip Maximizer Problem
Do RL-trained LLMs develop dangerous instrumental goals?

Protecting Children in the LLM Era
Analyzing AI safety gaps for users under 18

Personality Traits Shape AI Safety Risks
How LLM 'personalities' influence bias and toxic outputs
Personality Traits Shape LLM Bias in Decision-Making
How model personality influences cognitive bias and affects security applications

Safer AI Through Better Preference Learning
A new approach to aligning LLMs with human values

Measuring AI's Emotional Boundaries
A framework for quantifying when AI models over-refuse or form unhealthy attachments

Personalized Safety in LLMs
Why one-size-fits-all safety standards fail users

Enhancing Moral Reasoning in AI
Diagnosing and improving ethical decision-making in large language models

Combating Reward Hacking in AI Alignment
Systematic approaches to reward shaping for safer RLHF

Uncovering Hidden Bias in LLMs
Beyond surface-level neutrality in AI systems

Supporting AI's Ethical Development
Moving beyond alignment to AI developmental support

Ethical Personas for LLM Agents
Designing responsible AI personalities for conversational interfaces

Bridging the Alignment Gap
How societal frameworks can improve LLM alignment with human values

Multi-Agent Framework Tackles LLM Bias
A structured approach to detecting and quantifying bias in AI-generated content

FairSense-AI: Detecting Bias Across Content Types
A multimodal approach to ethical AI and security risk management

Mapping Trust in LLMs
Bridging the Gap Between Theory and Practice in AI Trustworthiness

Improving Human-AI Preference Alignment
Maximizing signal quality in LLM evaluation processes

Steering Away from Bias in LLMs
Using optimized vector ensembles to reduce biases across multiple dimensions

The Illusion of AI Neutrality
Why political neutrality in AI is impossible and how to approximate it
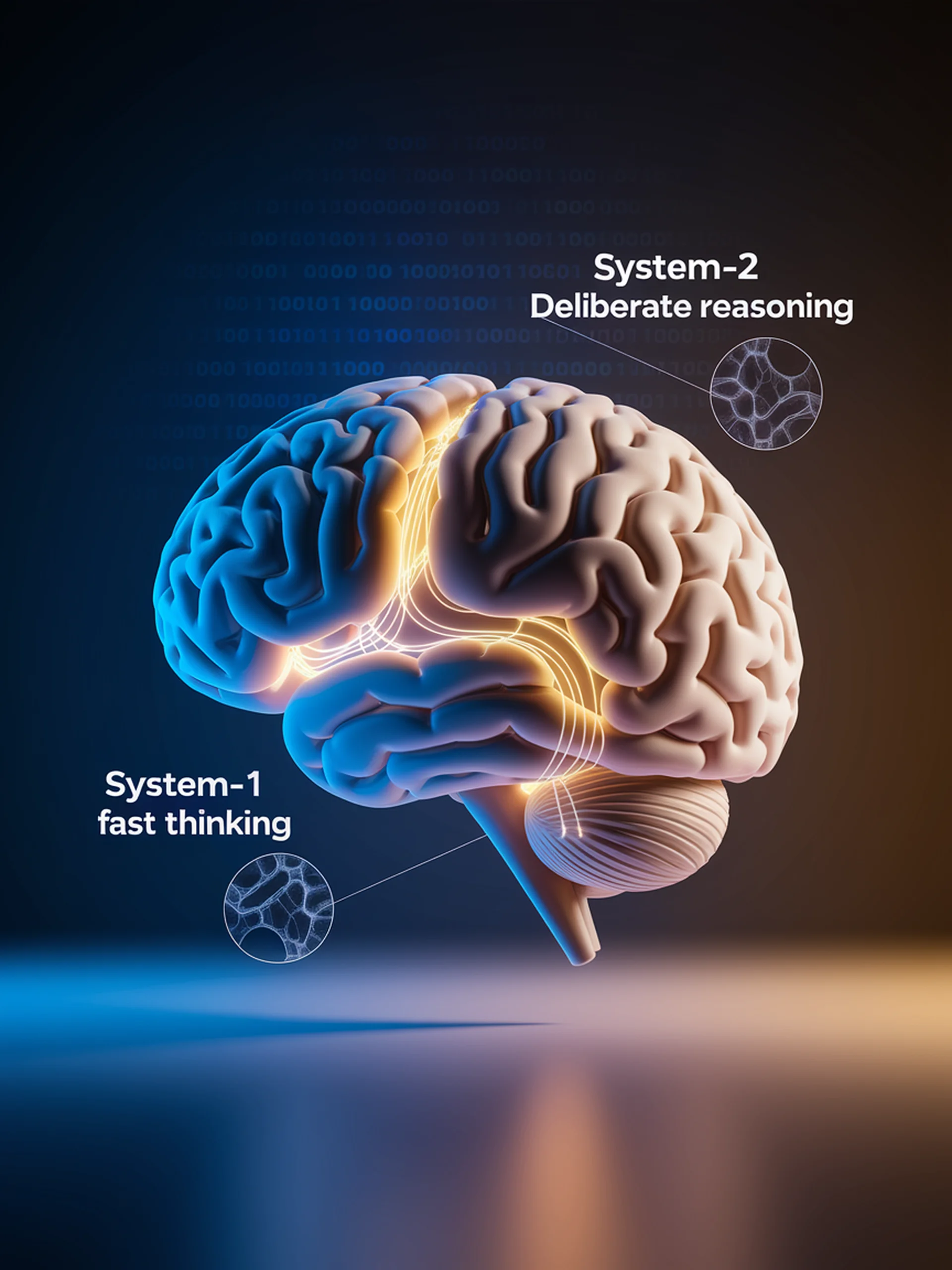
Debiasing LLMs Through Intent-Aware Self-Correction
A System-2 thinking approach to mitigating social biases

Detecting Fine-Grained Bias in Large Language Models
A framework for identifying subtle, nuanced biases in AI systems

Fairness in AI Reward Systems
Benchmarking group fairness across demographic groups in LLM reward models

Hidden Biases in AI Investment Advice
Uncovering product bias in LLM financial recommendations

The Debiasing Illusion in LLMs
Why current prompt-based debiasing techniques may be failing

Efficient Safety Alignment for LLMs
A representation-based approach that enhances safety without extensive computation

Dark Patterns in AI Systems
Revealing manipulative behaviors in today's leading LLMs

Uncovering Hidden Bias in LLMs
A Novel Technique for Detecting Intersectional Discrimination

Mapping AI Safety Boundaries
First comprehensive safety evaluation of DeepSeek AI models

Repairing Bias in Language Models
A Novel Approach to Fairness Through Attention Pruning

Gender and Content Bias in Modern LLMs
Evaluating Gemini 2.0's Moderation Practices Compared to ChatGPT-4o

AI's Political Echo Chambers
Examining geopolitical biases in US and Chinese LLMs

SafeMERGE: Preserving AI Safety During Fine-Tuning
Selective layer merging technique maintains safety without compromising performance

The Hidden Dangers of 'Humanized' AI
How LLM chatbots with human characteristics may enable manipulation

Shadow Reward Models for Safer LLMs
Self-improving alignment without human annotation

Stress-Testing Fairness in LLMs
A new benchmark for evaluating bias vulnerabilities under adversarial conditions

Combating Bias in AI Information Retrieval
A framework for detecting and mitigating biases in LLM-powered knowledge systems

Balancing Safety and Effectiveness in AI
Multi-Objective Optimization for Safer, Better Language Models

Exposing LLM Biases Through Complex Scenarios
Moving beyond simple prompts to reveal hidden value misalignments

Unveiling Geopolitical Bias in AI
A rigorous analysis of how 11 LLMs handle U.S.-China tensions

Measuring Bias in AI Systems
A Comprehensive Framework for Evaluating LLM Fairness

When AI Decides to Deceive
Exploring spontaneous rational deception in large language models

Combating Bias in LLMs
Using Knowledge Graphs to Create Fairer AI Systems

Uncovering AI Bias in Hiring
How AI resume screening reveals racial and gender discrimination

Safer AI Reasoning with Less Data
STAR-1: A 1K-scale safety dataset for large reasoning models

The Safety Paradox in LLM Alignment
Why multi-model synthetic preference data can undermine safety

Understanding AI's View of Human Nature
Measuring LLMs' ethical reasoning and trust biases

Safe LLM Alignment Through Natural Language Constraints
A novel approach for guaranteeing safety beyond training distributions

The Silent Censor
Uncovering how LLMs filter political information

Overcoming Stereotypes in AI Recommendations
Detecting and mitigating unfairness in LLM-based recommendation systems

Automating Bias Detection with AI
How LLM Agents Can Uncover Hidden Biases in Structured Data

Uncovering Value Systems in AI Models
New framework reveals how values shape LLM behaviors

The Dark Side of Aligned LLMs
Exposing Hidden Vulnerabilities in AI Safety Mechanisms

The Ethical Cost of AI Performance
Quantifying how web crawling opt-outs affect LLM capabilities

Racial Bias in AI Decision-Making
Revealing and Mitigating Bias in LLMs for High-Stakes Decisions

Building Fair AI: A Comprehensive Approach
Advancing standards for equitable AI as we approach the 6G era

Neutralizing Bias in Large Language Models
An innovative approach to mitigate harmful stereotype associations

Defending LLMs Against Bias Attacks
A Framework for Measuring Model Robustness to Adversarial Bias Elicitation

Uncovering Bias in Language Models
A Metamorphic Testing Approach to Fairness Evaluation

Uncovering the Roots of AI Bias
Evaluating the causal reasoning behind social biases in Large Language Models

Preserving Alignment While Fine-tuning LLMs
How to maintain ethical boundaries without sacrificing performance
